本文是电商数据实战系列第一篇。 数据来源:京东JData算法大赛-高潜用户购买意向预测。数据集以京东商城真实的用户、商品和行为数据(脱敏后)为基础。一直苦于缺乏实践,正好拿这个项目练练手。接下来的几篇实战博文,我会尽可能仔细的写下一些体会,结合之前学习的数据分析工具(以Python及相关包为主),探索一下电商数据的世界。由于本人也是数据分析的小白,希望在实践中和大家一起成长。
Update Log
- 2017/05/20
数据描述
以下数据描述来自数据介绍。
符号定义:
- S:提供的商品全集;
- P:候选的商品子集(JData_Product.csv),P是S的子集;
- U:用户集合;
- A:用户对S的行为数据集合;
- C:S的评价数据
训练数据部分: (这一部分就是我们拿到的数据) 提供2016-02-01到2016-04-15日用户集合U中的用户,对商品集合S中部分商品的行为、评价、用户数据;提供部分候选商品的数据P。
预测数据部分: 2016-04-16到2016-04-20用户是否下单P中的商品,每个用户只会下单一个商品。
数据表(四个):
- 用户数据
- 商品数据
- 评价数据
- 行为数据
我们接下来将逐一查看四个表各个字段值及特点。思考后续该如何挖掘数据最大价值?
准备工作
# 数据处理
import pandas as pd
import numpy as np
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
# 辅助类
import re
import os
%matplotlib inline
# 所有数据表
ACTION_2 = "JData_Action_201602.csv"
ACTION_3 = "JData_Action_201603.csv"
ACTION_4 = "JData_Action_201604.csv"
COMMENT = "JData_Comment.csv"
PRODUCT = "JData_Product.csv"
USER = "JData_User.csv"
NEW_USER = "JData_User_New.csv"
# 控制小数位数显示
pd.options.display.float_format = '{:,.3f}'.format
数据探查
初步估计:用户数据、商品数据、评价数据可直接读入内存,行为数据很大(我的电脑内存 8G),只能先读入一部分看看。
用户数据
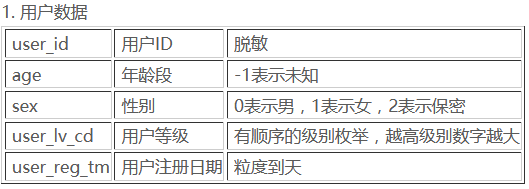
df = pd.read_csv('data_ori/' + USER, header=0, encoding="gbk")
df.shape
(105321, 5)
df.head()
| user_id | age | sex | user_lv_cd | user_reg_tm | |
|---|---|---|---|---|---|
| 0 | 200001 | 56岁以上 | 2.000 | 5 | 2016-01-26 |
| 1 | 200002 | -1 | 0.000 | 1 | 2016-01-26 |
| 2 | 200003 | 36-45岁 | 1.000 | 4 | 2016-01-26 |
| 3 | 200004 | -1 | 2.000 | 1 | 2016-01-26 |
| 4 | 200005 | 16-25岁 | 0.000 | 4 | 2016-01-26 |
最终数据要处理成矩阵形式,所以我们先把中文字符去除。
age
字段描述:-1表示未知
df.age.value_counts()
26-35岁 46570
36-45岁 30336
-1 14412
16-25岁 8797
46-55岁 3325
56岁以上 1871
15岁以下 7
Name: age, dtype: int64
def convert(age):
if age == '-1':
return -1
elif age == '15岁以下':
return 0
elif age == '16-25岁':
return 1
elif age == '26-35岁':
return 2
elif age == '36-45岁':
return 3
elif age == '46-55岁':
return 4
elif age == '56岁以上':
return 5
else:
return -1
df.age = df.age.map(convert)
x = df.age.value_counts().sort_index()
x
-1 14415
0 7
1 8797
2 46570
3 30336
4 3325
5 1871
Name: age, dtype: int64
sns.barplot(x=x.index, y=x.values)
<matplotlib.axes._subplots.AxesSubplot at 0x1cf9db75080>
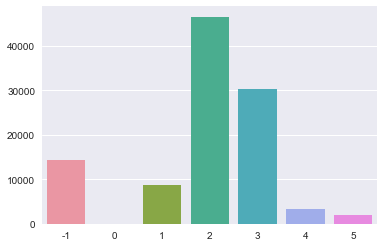
确实是中年人的购买力最旺盛呢。 接着我们需要计算一个指标user_reg_diff:即用户注册时间(参照为数据表中最早注册用户)。需要计算时间差值。
df['user_reg_tm'] = pd.to_datetime(df['user_reg_tm'])
min_date = min(df['user_reg_tm'])
df['user_reg_diff'] = [i for i in (df['user_reg_tm'] - min_date).dt.days]
df.head()
| user_id | age | sex | user_lv_cd | user_reg_tm | user_reg_diff | |
|---|---|---|---|---|---|---|
| 0 | 200001 | 5 | 2.000 | 5 | 2016-01-26 | 4,607.000 |
| 1 | 200002 | -1 | 0.000 | 1 | 2016-01-26 | 4,607.000 |
| 2 | 200003 | 3 | 1.000 | 4 | 2016-01-26 | 4,607.000 |
| 3 | 200004 | -1 | 2.000 | 1 | 2016-01-26 | 4,607.000 |
| 4 | 200005 | 1 | 0.000 | 4 | 2016-01-26 | 4,607.000 |
现在再来看一下数据表的基本信息。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 105321 entries, 0 to 105320
Data columns (total 6 columns):
user_id 105321 non-null int64
age 105321 non-null int64
sex 105318 non-null float64
user_lv_cd 105321 non-null int64
user_reg_tm 105318 non-null datetime64[ns]
user_reg_diff 105318 non-null float64
dtypes: datetime64[ns](1), float64(2), int64(3)
memory usage: 4.8 MB
可以看到三个字段有缺失值。
sex 字段
字段描述:0表示男,1表示女,2表示保密
df.ix[df.sex.isnull(), 'sex']
34072 nan
38905 nan
67704 nan
Name: sex, dtype: float64
df.sex.value_counts()
2.000 54735
0.000 42846
1.000 7737
Name: sex, dtype: int64
将缺失值用 2 填充。
df.ix[df.sex.isnull(), 'sex'] = 2
df.sex.value_counts()
2.000 54738
0.000 42846
1.000 7737
Name: sex, dtype: int64
输出数据
df.to_csv('data_ori/' + NEW_USER, index=False)
商品数据
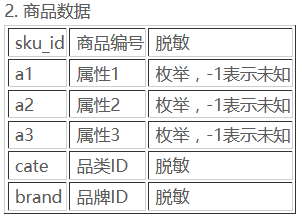
df = pd.read_csv('data_ori/' + PRODUCT, header=0)
df.head()
| sku_id | a1 | a2 | a3 | cate | brand | |
|---|---|---|---|---|---|---|
| 0 | 10 | 3 | 1 | 1 | 8 | 489 |
| 1 | 100002 | 3 | 2 | 2 | 8 | 489 |
| 2 | 100003 | 1 | -1 | -1 | 8 | 30 |
| 3 | 100006 | 1 | 2 | 1 | 8 | 545 |
| 4 | 10001 | -1 | 1 | 2 | 8 | 244 |
df.shape
(24187, 6)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 24187 entries, 0 to 24186
Data columns (total 6 columns):
sku_id 24187 non-null int64
a1 24187 non-null int64
a2 24187 non-null int64
a3 24187 non-null int64
cate 24187 non-null int64
brand 24187 non-null int64
dtypes: int64(6)
memory usage: 1.1 MB
df.describe()
| sku_id | a1 | a2 | a3 | cate | brand | |
|---|---|---|---|---|---|---|
| count | 24,187.000 | 24,187.000 | 24,187.000 | 24,187.000 | 24,187.000 | 24,187.000 |
| mean | 85,398.737 | 2.177 | 0.939 | 1.180 | 8.000 | 435.864 |
| std | 49,238.799 | 1.176 | 0.970 | 1.046 | 0.000 | 225.749 |
| min | 6.000 | -1.000 | -1.000 | -1.000 | 8.000 | 3.000 |
| 25% | 42,476.000 | 1.000 | 1.000 | 1.000 | 8.000 | 214.000 |
| 50% | 85,616.000 | 3.000 | 1.000 | 1.000 | 8.000 | 489.000 |
| 75% | 127,774.000 | 3.000 | 2.000 | 2.000 | 8.000 | 571.000 |
| max | 171,224.000 | 3.000 | 2.000 | 2.000 | 8.000 | 922.000 |
len(df.sku_id.value_counts())
24187
确认没有重复值,后续导入MySQL可以作为主键。
评价数据
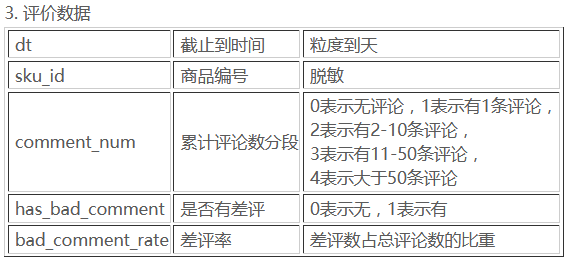
df = pd.read_csv('data_ori/' + COMMENT, header=0)
df.head()
| dt | sku_id | comment_num | has_bad_comment | bad_comment_rate | |
|---|---|---|---|---|---|
| 0 | 2016-02-01 | 1000 | 3 | 1 | 0.042 |
| 1 | 2016-02-01 | 10000 | 2 | 0 | 0.000 |
| 2 | 2016-02-01 | 100011 | 4 | 1 | 0.038 |
| 3 | 2016-02-01 | 100018 | 3 | 0 | 0.000 |
| 4 | 2016-02-01 | 100020 | 3 | 0 | 0.000 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 558552 entries, 0 to 558551
Data columns (total 5 columns):
dt 558552 non-null object
sku_id 558552 non-null int64
comment_num 558552 non-null int64
has_bad_comment 558552 non-null int64
bad_comment_rate 558552 non-null float64
dtypes: float64(1), int64(3), object(1)
memory usage: 21.3+ MB
len(df.sku_id.value_counts())
46546
df.dt.value_counts().sort_index()
2016-02-01 46546
2016-02-08 46546
2016-02-15 46546
2016-02-22 46546
2016-02-29 46546
2016-03-07 46546
2016-03-14 46546
2016-03-21 46546
2016-03-28 46546
2016-04-04 46546
2016-04-11 46546
2016-04-15 46546
Name: dt, dtype: int64
这里似乎发现,其实这个数据集就是对46546个数据条目,每周进行一次统计。
行为数据

# 读入1000行。
df = pd.read_csv('data_ori/' + ACTION_2, header=0, nrows=10000)
df.head()
| user_id | sku_id | time | model_id | type | cate | brand | |
|---|---|---|---|---|---|---|---|
| 0 | 266,079.000 | 138778 | 2016-01-31 23:59:02 | nan | 1 | 8 | 403 |
| 1 | 266,079.000 | 138778 | 2016-01-31 23:59:03 | 0.000 | 6 | 8 | 403 |
| 2 | 200,719.000 | 61226 | 2016-01-31 23:59:07 | nan | 1 | 8 | 30 |
| 3 | 200,719.000 | 61226 | 2016-01-31 23:59:08 | 0.000 | 6 | 8 | 30 |
| 4 | 263,587.000 | 72348 | 2016-01-31 23:59:08 | nan | 1 | 5 | 159 |
len(df.model_id.value_counts())
37
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 7 columns):
user_id 10000 non-null float64
sku_id 10000 non-null int64
time 10000 non-null object
model_id 5511 non-null float64
type 10000 non-null int64
cate 10000 non-null int64
brand 10000 non-null int64
dtypes: float64(2), int64(4), object(1)
memory usage: 547.0+ KB
没看懂这个model_id是什么,似乎有很多缺失值。
总结
至此,我们已经对每个数据表进行了初步的探索和分析。因为数据表很大,一般的个人PC可能不足以支撑。在下一篇中,我将结合关系型数据库管理系统——MySQL来创建训练数据用的表。
Reference